
Azure Storage is the foundation of the whole of Azure. Every service either runs directly on top of Azure Storage (VMs, PaaS Services) or relies on Azure Storage for many of its operations. With such an important role, it’s not surprise that Microsoft has invested a lot of time and effort to make this service as fast and resilient as possible while keeping the associated cost or running and maintaining the service ridiculously low.
Azure Storage needs to be resilient and secure to allow business-critical workloads to run. Durability is achieved by using a combination of multiple copies and strong consistency: This system is at least as resilient as traditional RAID. Investment has also been made to make the hardware more resilient to drive and rack level failures. Any failure is transient to users and resolved faster than can be achieved with traditional on-premises enterprise storage. Data integrity protection is provided with full CRC and background scrubbing to prevent silent data corruption or bit rot. Users also have the option to enable geo-replicated storage which copies data across two distant geographical regions to achieve high data availability in case of a regional level disaster. Replication is carried out across data centers that are hundreds of miles apart. Finally, Azure Storage was built with security as a priority, and users have a variety of options ranging from encryption at rest to easy client side encryption and key management using Azure Key Vault.
Azure Storage components

All three cloud platforms (Infrastructure, Platform, and Software) rely on Azure Storage. This article will provide a deep dive into the details of Azure Blob Storage.
Blob Storage Service
Blob Storage Service caters for object storage that can be used to store and serve unstructured data. This data can range from App and Web data to images, files, Big Data from IoT and, of course, backups and archives. The service allows the Azure user to store Petabytes of data with strong consistency and low cost. The Blob Storage Service is designed to be highly available with a 99.9% SLA for normal storage and 99.99% SLA for RA-GRS replicated storage.
Blob Storage Durability.
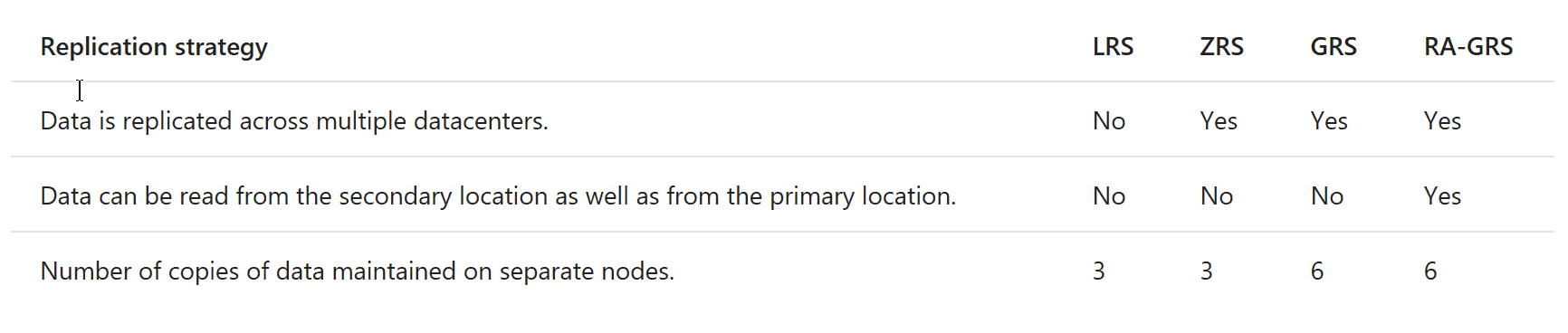
There are 4 types of storage durability:
- Local Redundant Storage (LRS)
- Zone Redundant Storage (ZRS)
- Geo Replicated Storage (GRS)
- Read Access Geo Replicated Storage (RA-GRS)
LRS storage stores three replicas of your data in a single region to protect against disk, node and rack failures. ZRS is similar to LRS but splits the data across two datacentres in the same region. This makes the data more resilient over simple LRS, which is the default option.
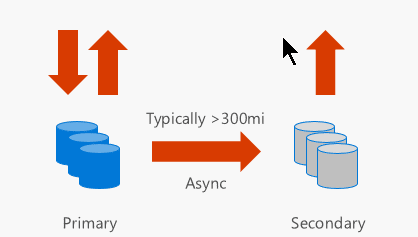
GRS stores six replicas in two different regions (e.g. North and West Europe) to protect against major regional disasters as well. Replication to the secondary region is performed asynchronously. It’s important to note that there’s a cost associated with the data transfer operation between different datacentres.
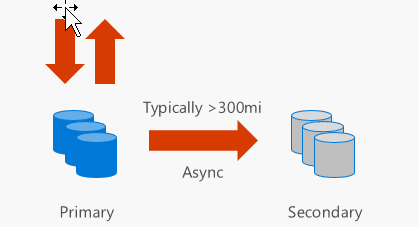
Finally, RA-GRS provide read-only access to the secondary storage through an accessible endpoint to allow for load-balanced queries. This can be extremely useful for geo-replicated applications that need to have quick access to blob storage data without having to deploy a Content Delivery Network (CDN). Similarly to GRS, there’s an associated data transfer cost for data that is replicated across different datacentres.
The following table provides a good replication summary overview
Types of Blobs
Block Blobs
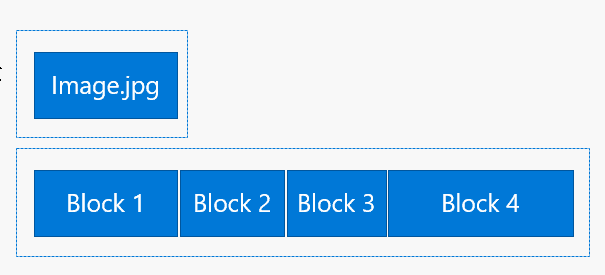
Block blobs are designed for object storage, such as documents, images, video, Click-once solutions etc. It’s highly optimized for sequential access. Each blob is made up of a series of blocks each of which is identified by a block ID. Blocks can have different sizes but the maximum size is 100MB and the maximum number of block blobs can be up to 50,000MB. Consequently, the maximum Block Blob size is 4.75TB (up from 1TB max up until recently). If you’re using the REST API, the sizes are different and the maximum blob size is 195GB.
Append Blobs
Append blobs are very similar to block blobs, in that they are comprised of blocks but they are highly optimized for ‘append’ operations. New data is only appended as blocks at the end of the blob (hence the name). Append blobs don’t allow deleting or updating of existing block blobs. The maximum size of a block append blob is 4MB and the maximum size of an append blob is 195GB. This type of blob is ideal for multi-writer append-only scenarios such as logging or big data analytics output.
Page Blobs
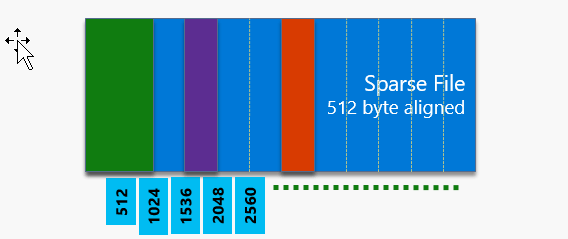
Page blobs are optimized for random read and write operations. In contrast to the elasticity of the previous block and append blob types, page blobs are initialized with a maximum size or capacity and they can’t grow bigger than that. Page blobs consist of 512-byte pages so when you add or update the contents of a page blob, you write the data by specifying an offset and a range that align with this 512-byte boundary. The maximum size of a single write operation can be up to 4MB. The maximum capacity of a page blob is 1TB. Because page blobs are what we use today when we attach a data disk to an Azure Virtual Machine and because this 1TB is fairly limited, there are plans to significantly increase the maximum page blob size. This will align nicely with current enterprise needs for larger disks, especially from a backup and disaster recovery perspective. Azure Site Recovery is an invaluable service for DR and HA but the limited page blob size has been an issue preventing many companies using it because they tend to run VMs with much larger disks. It’s extremely exciting that this limit will be lifted very soon.
Blob Naming Conventions
Like everything else on Azure, there are specific naming conventions when it comes to naming blobs and containers in a Storage Account. To begin with, the Storage Account name needs to be globally unique. The Storage Account URI that gets generated, contains the account name only, for example https://myaccount.blob.core.windows.net.
Container naming rules
A container name must be a valid DNS name and as such, it needs to conform to the following naming rules:
- Name must start with a letter or number, and can contain only letters, numbers, and the dash (-) character.
- Every dash (-) character must be immediately preceded and followed by a letter or number
- Consecutive dashes are not permitted in container names.
- Only lowercase letters are allowed.
- Names can be between 3 and 63 characters long.
Blob naming rules
A blob name must to the following naming rules: +
- Blob names are case-sensitive
- Blob name can contain any combination of characters.
- Blob names can be between 1 and 1,024 characters long.
- Reserved URL characters must be properly escaped but generally should be avoided
Types of storage
Standard Storage
When deciding on Azure Storage offerings, performance and cost are two important factors. For normal workloads, the default option is Standard storage. This SKU runs on normal, commodity spinning disks. The pricing is optimised around frequent read/writes across all 4 redundancy models
Premium Storage
For high-performance, low latency disk support, you can choose Premium Storage. Unlike the Standard SKU, premium storage stores data on solid state drives (SSDs) which can deliver up to 2000 MB/s in terms of disk throughput with extremely low latency for read operations.
Cool Storage
This service is geared towards infrequent access and it is designed for the purpose of archiving data, such as database and VM backups. The API and SDKs between hot and cool storage are identical, making it easy to work with either offering but cool storage comes with a significantly reduced cost. The only caveat is that you don’t access the data as frequently. If you do, then the cost for reading data is higher. In terms of SLAs, throughput and performance the two services are also identical.
Working with Blob Storage
Client libraries and SDKs
The client libraries simplify the task of working with Azure storage services by implementing convenient features and hiding away the complex authentication and connection logic. By using the client SDKs (I will lump PowerShell and Azure CLI in there) you get automatic chunking of data into the appropriate block sizes, parallel uploads, asynchronous operations, transient connection failure handling and client side encryption. The following operations are supported
- PutBlob – this executes a single REST call for data up to 64MB in size. A new PutBlob operation over an existing object will replace the data
- PutBlock/PutBlockList – this will split the data to be uploaded into blocks and it comes with efficient continuation and retry logic built-in. It will also execute the upload in parallel with out-of-order uploads and allows for intra-object de-duplication
- GetBlob – returns the blob data, properties and all metadata and you can use the checksums returned in the response to validate the integrity of the data. The ‘read’ operation supports ranges in order to build parallel downloads of large blobs
- CopyBlob – it executes a full copy while discarding any uncommitted blocks and snapshots. Copies may complete asynchronously so you need to check the progress using the CopyId. Copies within the same storage account are fast but copies from, and to, external sources can be slower depending on the source
- ListBlobs – this is a container-level operation and can be used to list up to 5000 blobs at a time. To improve performance, you can use filtering (“Begins With”) or traversing
- DeleteBlob – deletes a blob, along with metadata and snapshots. For bulk deletes, you may want to consider DeleteContainer instead
REST API
Because all Azure SDKs are, effectively, smart wrappers of the underlying REST API calls, Azure exposes this REST API to allow you to consume any service. The Azure Storage REST API is available to use but there are a few caveats you need to be aware of
- Some blob operation will be limited in terms of data sizes
- Parallel operations are not supported
- Continuation needs to be coded
- Fault handling needs to be done manually
AzCopy
This is a utility that is optimized to work with the Azure Blob storage at scale. The AZCopy tool simplifies data migration by providing an efficient way to copy millions of files, whatever their size. It includes journaling for reliability and supports Blob, Table and File storage. It’s built on top of the Azure Data Movement Library which is designed for large data movement. Consequently, when faced with large data-movement requirements, you can either use AzCopy or create a custom tool using the exact same APIs provided by the Azure Data Movement SDK. AzCopy comes with both a CLI for task automation or a GUI for ad-hoc tasks
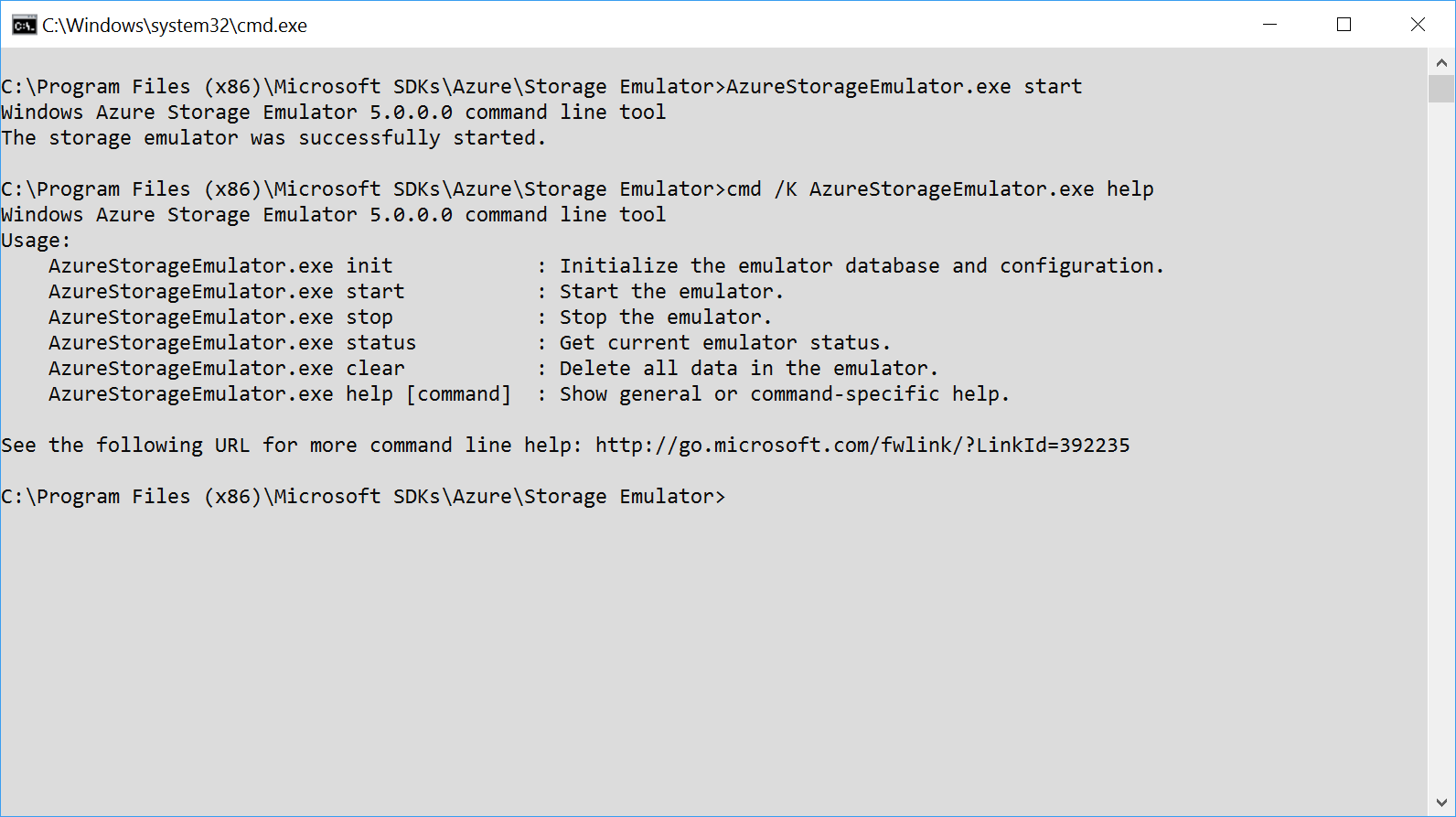
Azure Storage Emulator
To integrate your application with the Azure Storage Account, you will usually need some testing. Instead of using the “real thing”, you have the option to use the Storage Emulator to allow you to develop locally. The Storage Emulator is part of the Azure Storage SDK so it gets installed automatically. It runs as a self-hosted service and listens for any incoming calls. Some operations and types of Storage are not supported:
- The maximum supported blob size in the emulator is 2 GB.
- ‘Incremental Copy Blob’ can be used to copy snapshots from overwritten blobs but this will return a failure on the service.
- ‘Get Page Ranges Diff’ does not work between snapshots copied using ‘Incremental Copy Blob’.
- A ‘Put Blob’ operation may succeed against a blob that exists in the storage emulator with an active lease, even if the lease ID has not been specified in the request.
- ‘Append Blob’ operations are not supported by the emulator.
To use the storage emulator, you need to set the Azure Storage Connection string to UseDevelopmentStorage=true
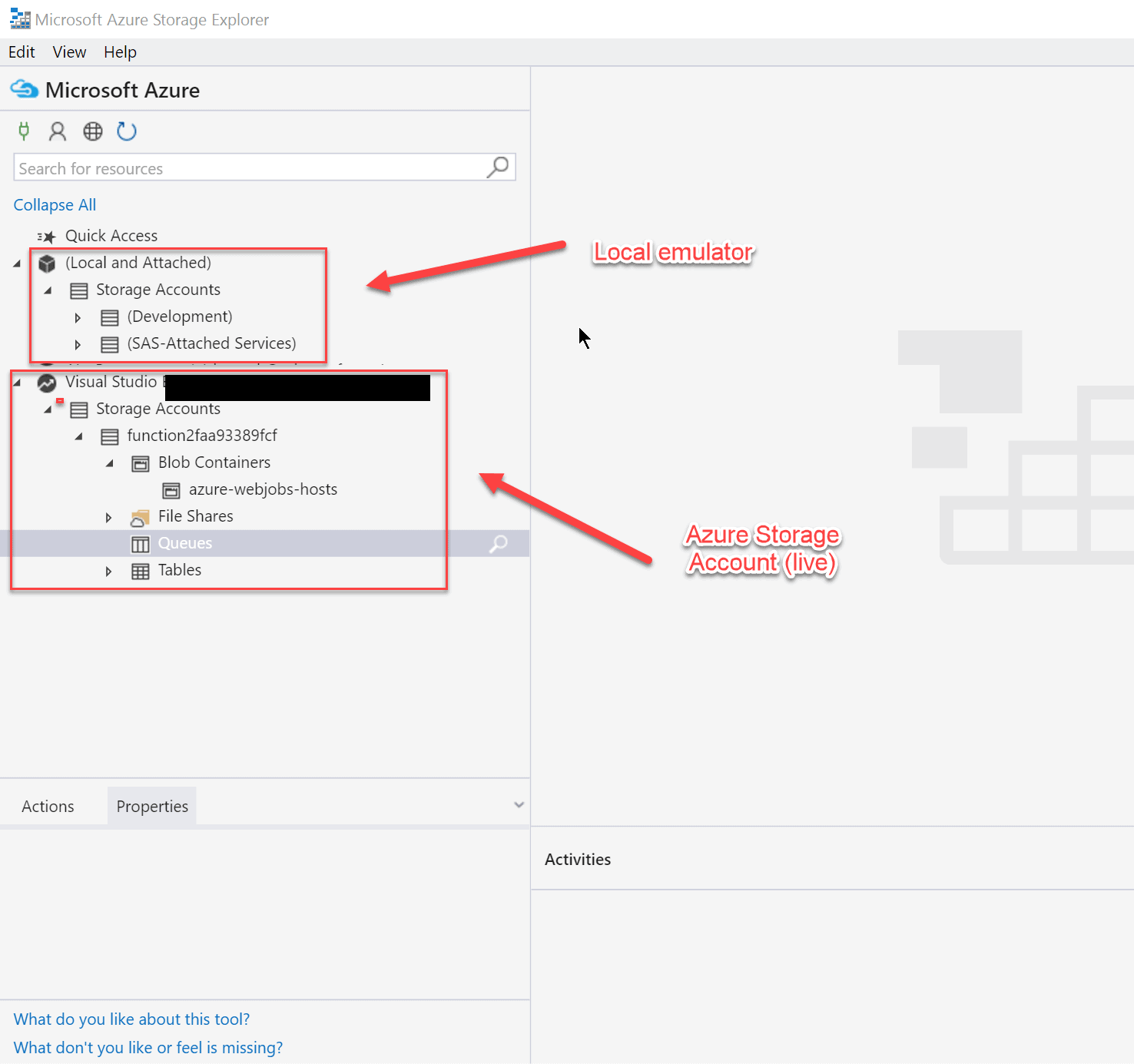
Azure Storage Explorer
This is a cross-platform, GUI-based, tool that allows you to manage your storage account using a very nice and lightweight interface built with Electron and Node.js. It comes with some clever features and makes it easy to work with blobs, containers, tables etc. without having to fall into code. The reason why the Azure Storage Explorer will become an invaluable tool as you develop solutions that consume Azure Storage is because it allows you to check data stored against the local emulator
Summary
Azure Blob Storage is one of the most versatile and heavily deployed services on Azure: It allows for easy decoupling and storage for your application and backup data at a fraction of the cost of on-premises storage. Because you pay only for the data used, it’s flexible and can scale as your operations and your needs evolve.